(Come piegare la carta in modo creativo e nel frattempo capire le reti neurali)
Sappiamo bene o male dalla storia che un giorno un tizio ha scoperto che fondendo minerali si poteva fare a meno di scheggiare la selce e con il passare del tempo tutti hanno capito cosa fossero i metalli pur non essendo fabbri.
Un altro giorno un tizio ha scoperto che le ruote girano, un altro che le stampe stampano e poi un altro che le industrie si industriano. E potremmo senza ombra di dubbio affermare che, nel tempo, cogliere la parte intuitiva di ogni salto tecnologico sia rimasta una cosa potenzialmente alla portata di chiunque.
Anche i computer, per quanto siano digitali, mantengono un approccio “analogico”: se un tizio clicca un pulsante su una pagina web, ha bene o male chiaro in testa che da qualche parte un altro tizio un giorno ha capito come programmarlo su un computer che un altro tizio ha inventato per trasmettere il suo gesto alla macchina in una serie di stati finiti.
Con l’Intelligenza artificiale no, questa consuetudine tra nuove tecnologie ed esseri umani si è rotta. Nella maggior parte dei casi, una risposta da un chatbot basato su un Large Language Model viene considerata magia. Si sa che più o meno da qualche parte altri tizi stanno compiendo riti esoterici di cui si fa fatica ad avere anche una vaga intuizione.
Questo è il primo di una serie di articoli/esperimento sull’intelligenza artificiale che si pongono l’obiettivo (o almeno il tentativo) di ristabilire quello strato di intuizione che dovrebbe collegare le persone alla tecnologia. Il tutto partendo dal presupposto personale che, per avere un’idea corretta dell’AI, sia necessario capire di cosa stiamo parlando dal punto di vista matematico.
Se c’è un aspetto che ho sempre ammirato di matematici come Israel Herstein (noto per rendere l’algebra astratta accessibile senza tradirne il rigore) è la chiara intenzione nei suoi testi di voler far comprendere una materia che a molti pare irrimediabilmente ostica. Siccome per me la matematica è una strana e meravigliosa forma di pittura, vediamo se, senza rinunciare troppo alle formule, si riuscirà a dare una descrizione di una tecnologia che ormai è arrivata a tutti. Naturalmente lo stile sarà più vicino a “Herstein spiega l’algebra in trattoria”.
Perciò, fatte le premesse, l’argomento di questo primo articolo è: le reti neurali. Vedremo che non sono altro che origami fatti di equazioni e che capirlo non richiede di essere matematici, ma solo di avere la pazienza di piegare un foglio.
Cosa rende questo orsacchiotto veramente coccoloso?
Da una parte un orsacchiotto, dall’altra una curva ottenuta mettendo su un grafico un insieme di dati di input $\boldsymbol{x}$ e un insieme di dati $\boldsymbol{y}$.
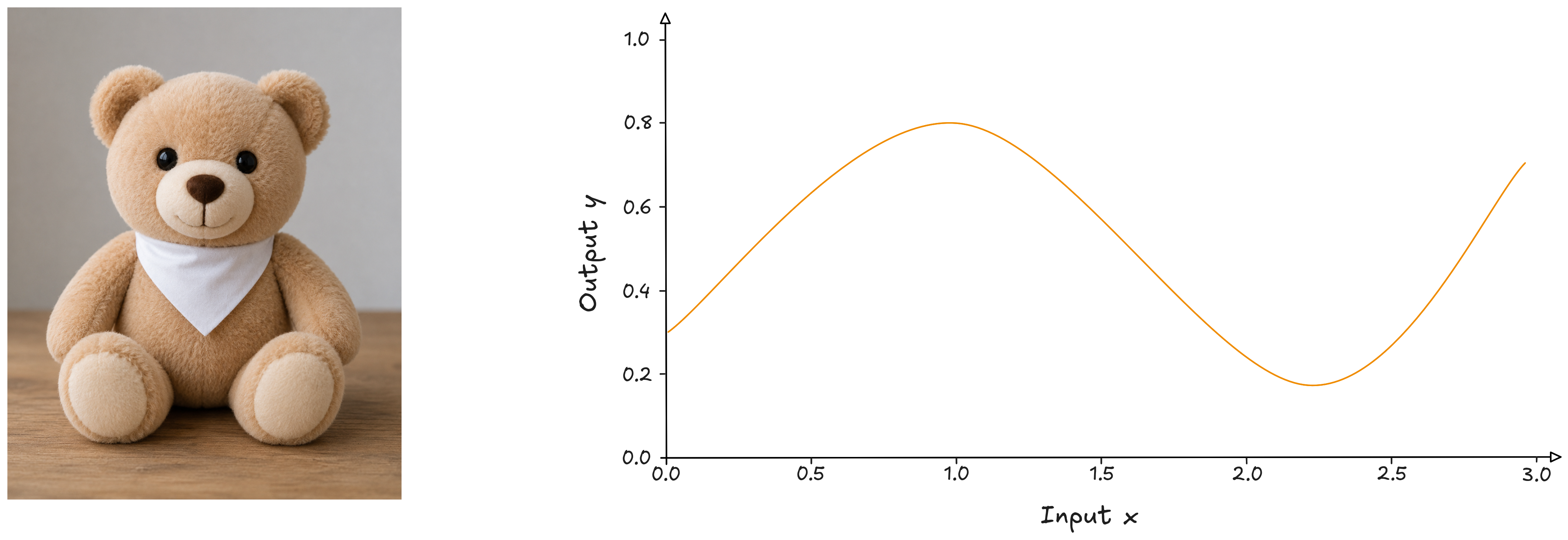
C’è un modo per catturare l’essenza coccolosa dell’orsacchiotto con un origami? Se ci riuscissi avrei un modello in grado di riprodurre una base su cui costruire un esercito di orsacchiotti con la possibilità magari di aggiungere anche nuove caratteristiche coerentemente coccolose.
Quella curva invece potrebbe essere il prodotto di una funzione matematica che la genera. Come faccio a capire l’essenza di quella curva? Chiameremo questa funzione $y = f(x)$. Non la conosciamo, ma se riuscissimo a modellarla, avremmo una funzione in grado, non solo di replicare i dati noti, ma anche di generarne di nuovi in modo coerente con il contesto in cui vivono i dati originali.
Un foglio bianco e una retta
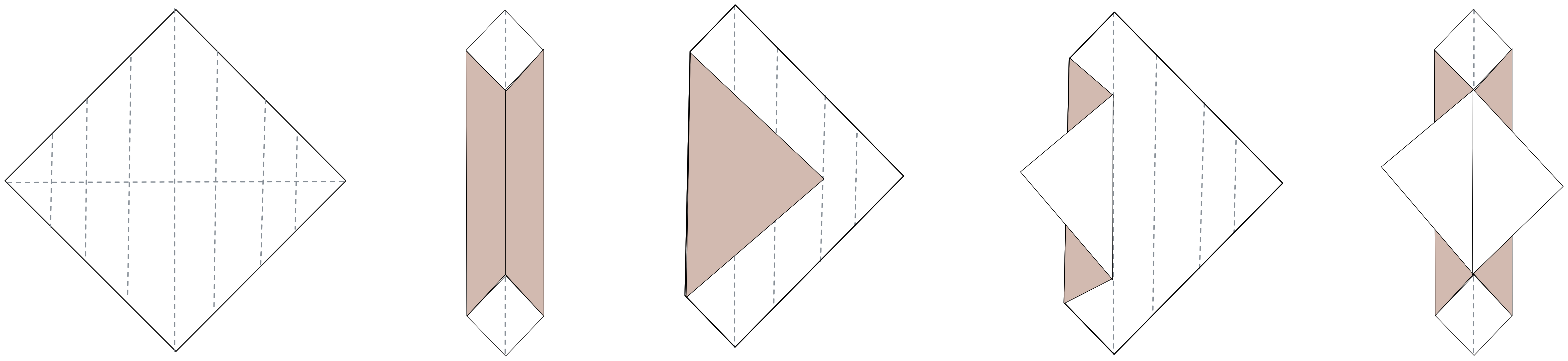
Stiamo facendo un origami e da dove partire se non da un foglio bianco. Primo passo: pieghiamolo in due.
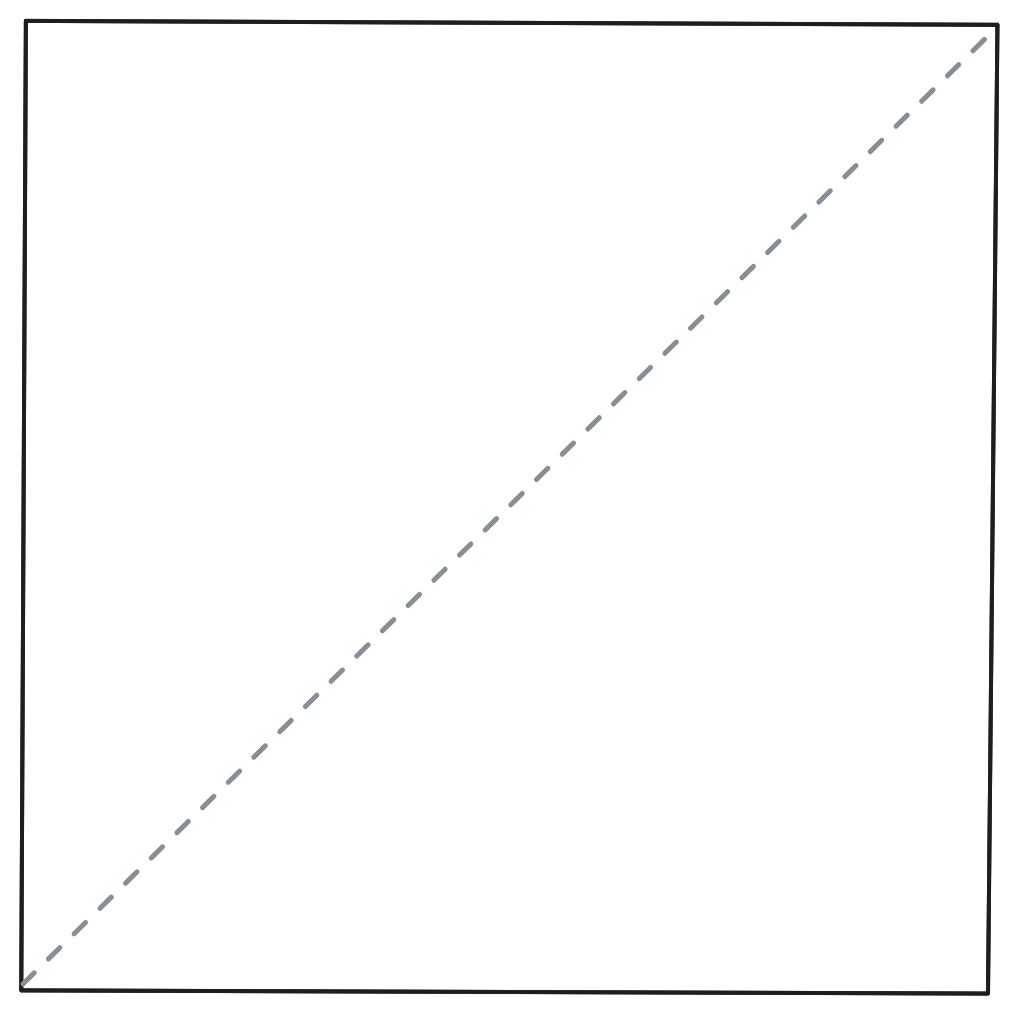
Procediamo allo stesso modo nella parte matematica, vogliamo raggiungere una funzione ideale, ma senza andare in giro per teoremi, partiamo da un’equazione semplice: la retta.
$$ y = \alpha \cdot x + \beta $$dove:
- $x$: è la parte del dataset che rappresenta gli input
- $y$: sono gli output che conosco e che userò come esempio
- $\alpha$: il coefficiente angolare, quel valore che quando cambia, cambia anche l’orientamento della retta
- $\beta$: l’intercetta, quel valore che sposta la retta dal centro degli assi spingendola in su e in giù in base al segno
Quando studiamo questo tipo di equazioni a scuola dobbiamo cercare un valore $x$ tale che, una volta inserito nell’espressione di cui già conosciamo la $y$, sia in grado di renderla vera. Ad esempio: in $2x + 3 = 7$ il valore che verifica l’espressione è $x = 2$.
Ma qui le cose sono diverse: conosciamo sia i dati di input che i dati di output. È qui che cambia tutto: non cerchiamo più l’incognita nell’input, ma nei parametri del modello. I valori da trovare sono $\alpha$ e $\beta$.
Chiameremo questi valori parametri e sarà la loro ricerca a determinare il successo o meno del nostro modello.
Quindi alla fine, a prescindere dalla complessità, avrò un modello che, a partire dai dati di input $\boldsymbol{x}$ e trovati i parametri adatti $[\alpha, \beta]$, mi darà risultati coerenti con l’output $\boldsymbol{y}$.
$$ \begin{align*} y &= f(x, \alpha, \beta) \\ &= x \cdot \alpha + \beta \end{align*} $$Chi ben comincia…
Ora, se penso ad un parametro da mettere in conto nel mio origami, il primo è sicuramente la rotazione del foglio. Andando per intuizione, lavorando sugli angoli, potrei avere molte più possibilità di rappresentazione.
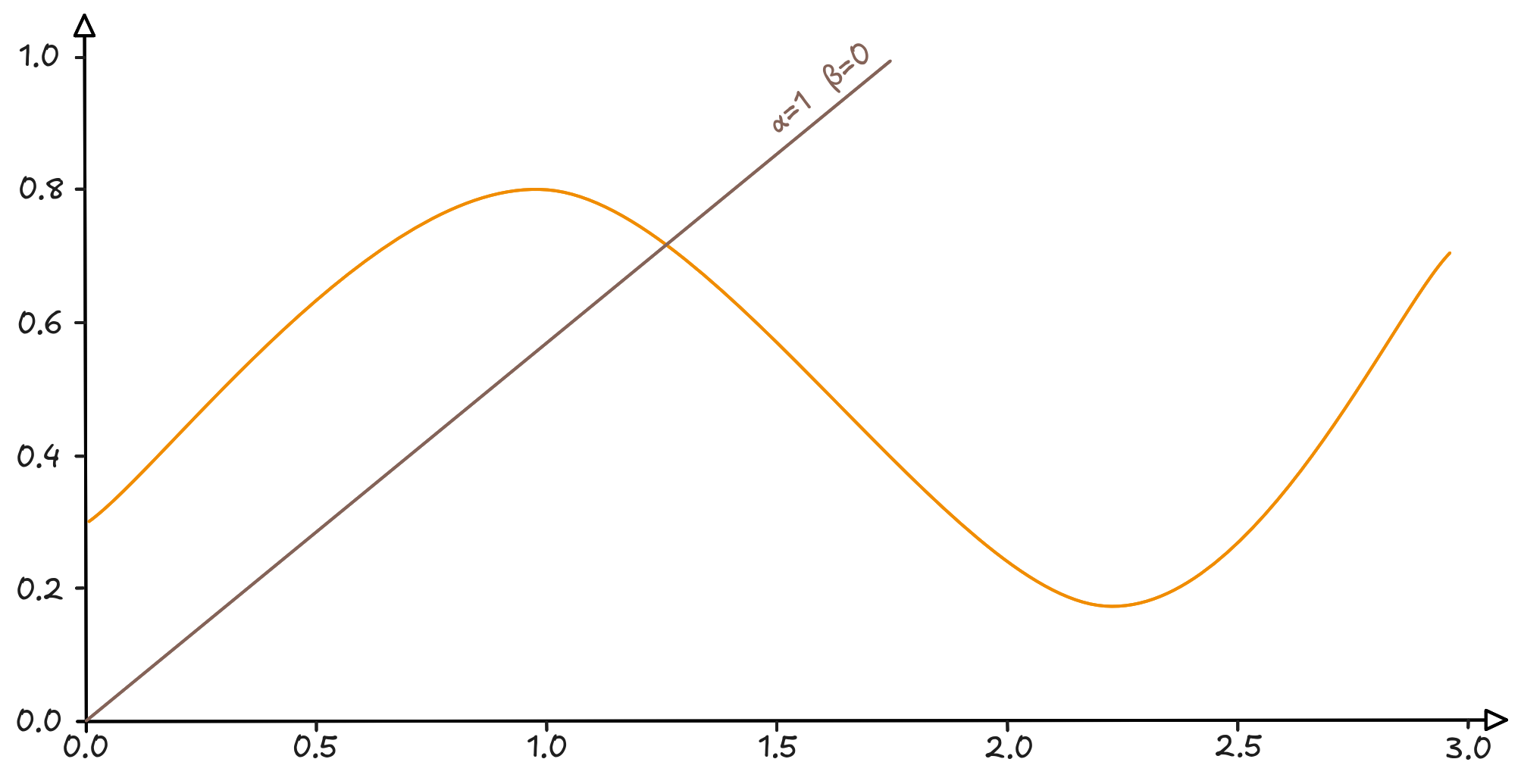
Certo, siamo ancora ben lontani dall’immagine di un orsacchiotto, tuttavia se guardo l’originale e se ruoto di 45 gradi il foglio, quest’ultimo dà già l’idea di contenere il risultato finale.
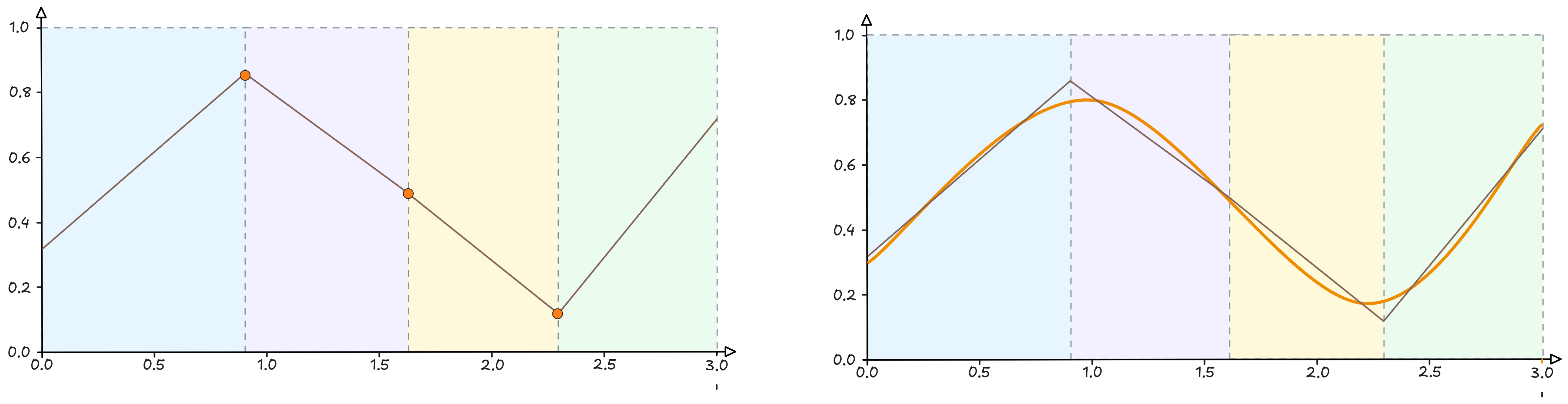
Mentre, se penso ai due parametri della retta, notiamo che cambiarne il valore è un po’ come spostare quest’ultima in su e in giù per il grafico, ruotando finché non trovo la posizione utile a “sintetizzare” la curva al meglio.
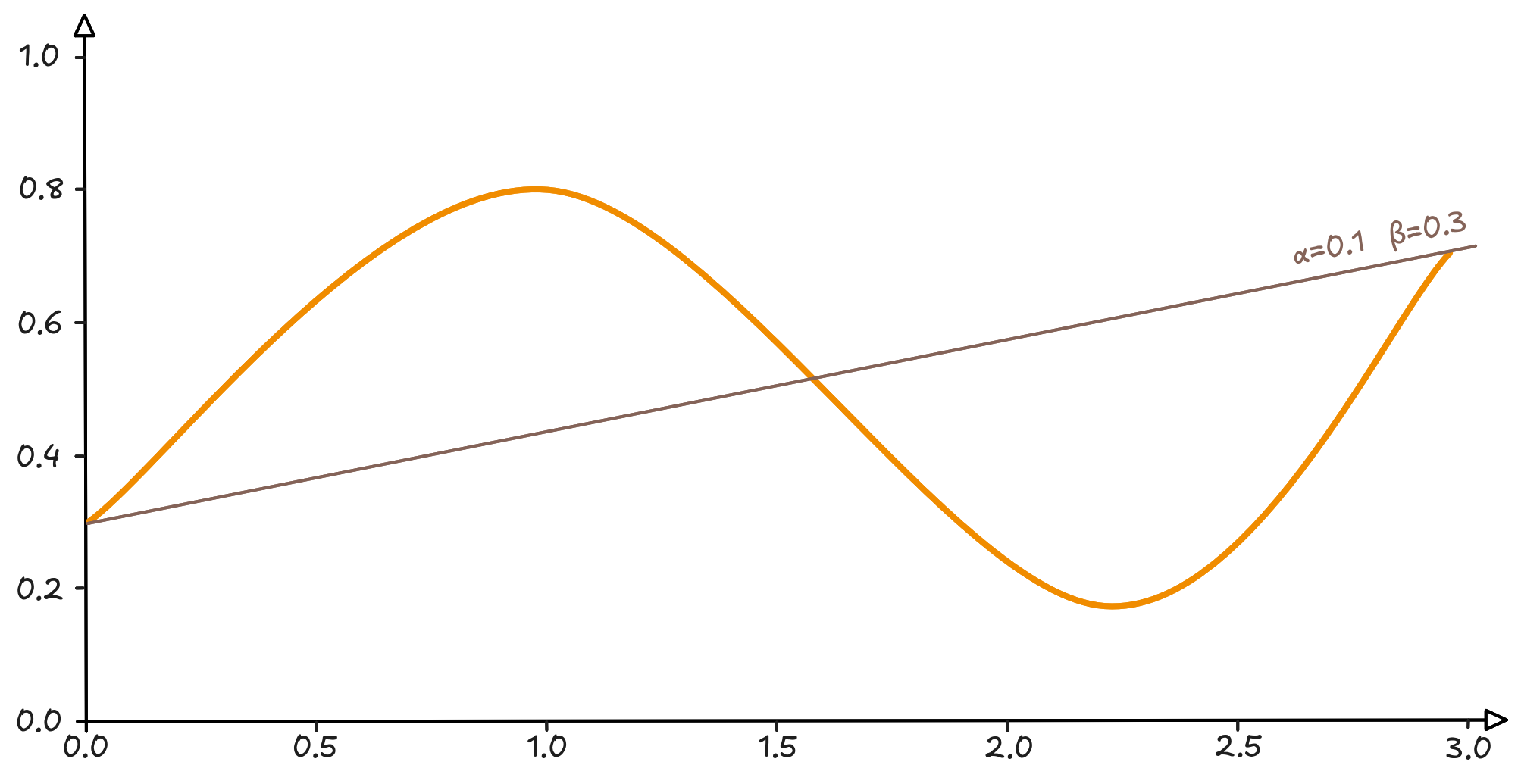
Non male, abbiamo trovato una retta che passa esattamente in mezzo alla curva.
Possiamo considerarla una sintesi? Assolutamente sì. Cerchiamo di cogliere un punto fondamentale: la retta passa più o meno in mezzo e separa la curva in due parti più o meno uguali. Tradotto in altri termini: l’errore che commetto approssimando la curva con una retta $y = 0.1x + 0.3$ è quantificabile e potremmo arrivare a descrivere questo errore in qualche modo.
Quindi, siamo sicuri che prolungando la retta l’errore con cui si approssima la curva nei nuovi punti sarà coerente con quello sui punti noti? La risposta più adatta a questa domanda è e sarà sempre: Assolutamente Forse.
Mettiamo quindi in chiaro un concetto che personalmente credo vada scolpito sulla roccia ogni volta che si parla di AI:
“le sole e uniche due parole importanti nell’Intelligenza artificiale sono: accettabile e trascurabile”.
Va capito, e lo capiremo strada facendo, che per quanto possa essere raffinato o complicato un modello, questo avrà sempre un margine di errore che, per quanto minimizzato, non potrà in alcun modo far pronunciare ad alcuno le fatidiche frasi: “la nostra soluzione arriva ad un’accuratezza vicino al 100%”. Se ascoltate una frase del genere… fuggite!
Piegare lungo i bordi
È arrivato il momento di dare struttura al nostro origami. Dobbiamo scegliere le pieghe iniziali, quelle che guideranno il resto dei passi. Partiamo da creare quattro zone distinte, ben posizionate, in grado di contenere le pieghe di dettaglio.
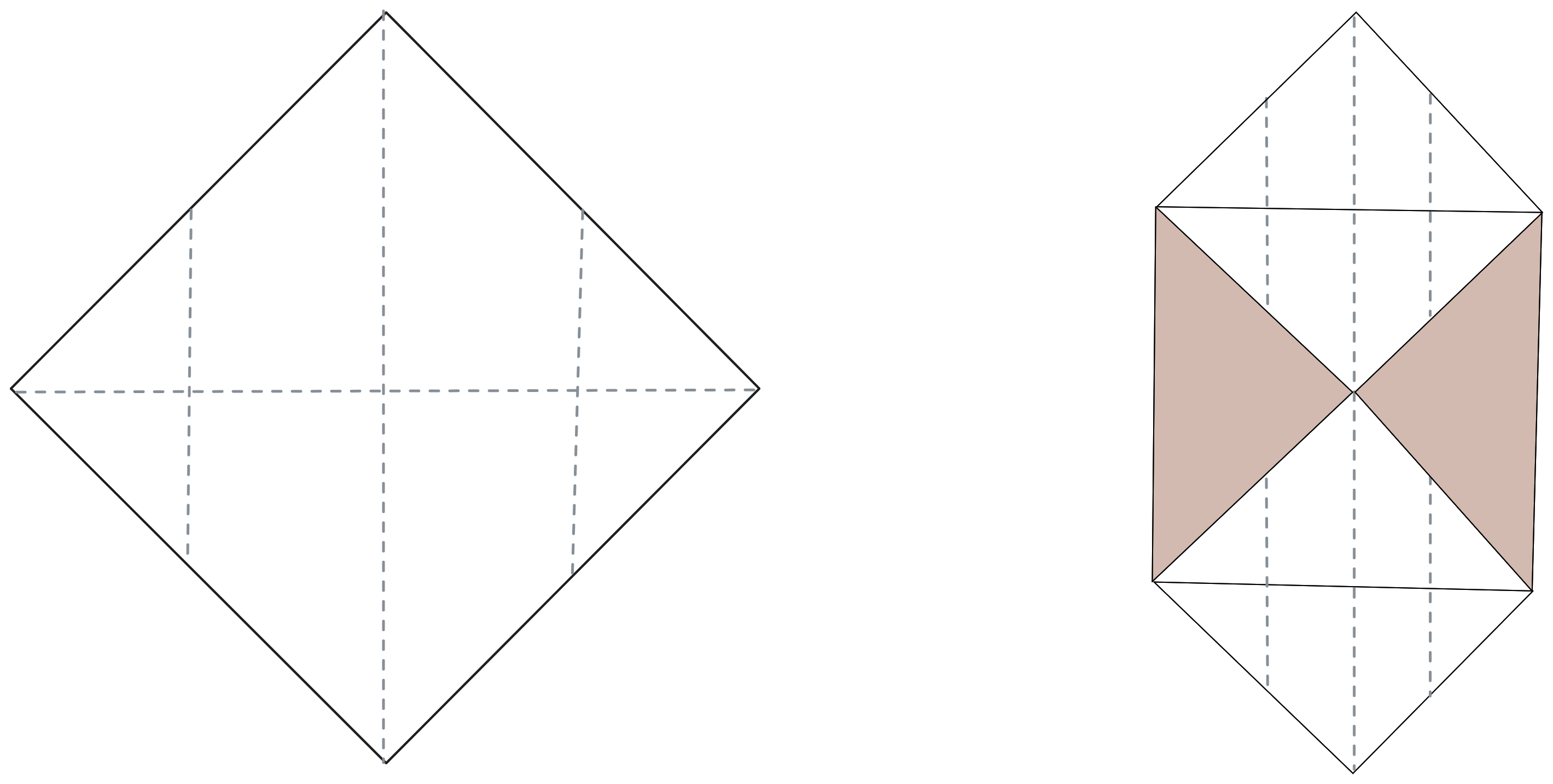
Notiamo che le pieghe attive, più esterne, determinano la possibilità di evolvere la nostra struttura con la possibilità di avere nuova geometria su cui lavorare. Le due pieghe interne, per ora, sono inattive, ma sono lì e nei passaggi successivi sicuramente torneranno utili.
E per la curva? Procedo esattamente con la stessa logica. È chiaro che una sola retta non è l’ideale per rappresentare una curva, perché non “piegarla” in modo da ricavare quattro zone ben distinte?
Cominciamo dal passare da una a tre equazioni:
$$ \begin{align*} h_1 &= x \alpha_1 + \beta_1 \\ h_2 &= x \alpha_2 + \beta_2 \\ h_3 &= x \alpha_3 + \beta_3 \end{align*} $$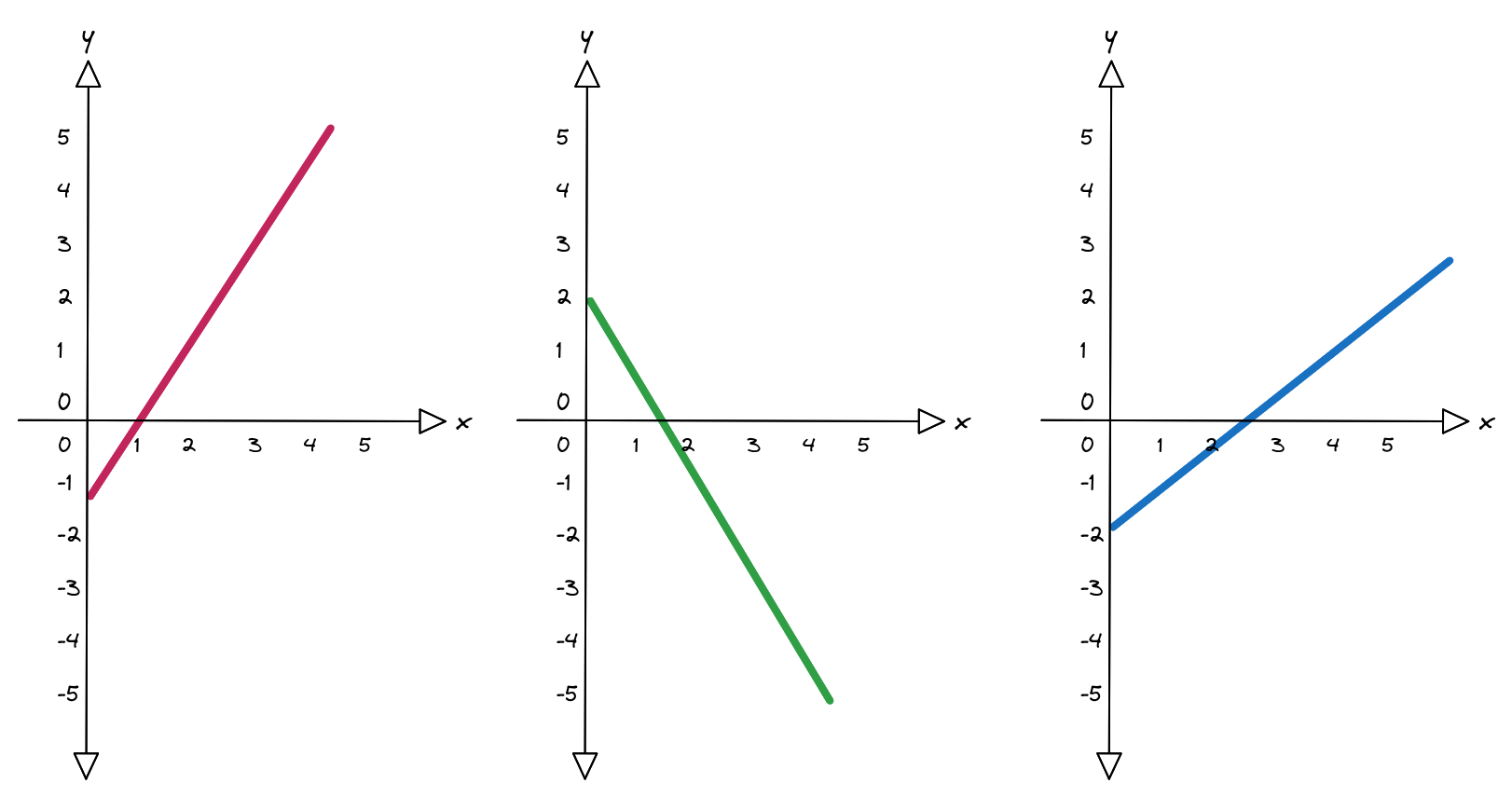
Ora abbiamo tre equazioni, ma dovremmo mettere in conto il fatto che, essendo tre linee continue, è un po’ complicato capire come unirle. Bisognerebbe inserire dei breakpoint, dei punti di giuntura con cui unire le tre equazioni.
Prima facciamo una distinzione, molto semplificata, che però va fatta per capire la matematica a seguire. Una relazione lineare tra input $x$ e output $y$ cambia in modo costante e proporzionale: se raddoppi la causa, raddoppi l’effetto, formando una linea retta sul grafico. Una relazione non lineare cambia invece in modo variabile formando curve o oscillazioni. In questo caso, piccoli cambiamenti iniziali possono causare risultati finali enormi o sproporzionati.
C’è un problema però: sommare funzioni lineari produce sempre una funzione lineare. Se combinassimo le tre rette così come sono, otterremmo un’unica retta, più complicata da calcolare ma altrettanto rigida. Per “piegare” davvero le equazioni abbiamo bisogno di qualcosa che introduca una discontinuità, un punto in cui il comportamento cambia.
Cerchiamo di trarre qualcosa di utile da questa spiegazione.
- Passare da una rappresentazione lineare a non lineare ci torna utile per comporre le rette in modo da avvicinarci alla curva target.
- La non linearità porta grandi poteri ma anche grandi responsabilità (piccoli cambiamenti possono causare risultati inutilizzabili).
- Abbiamo visto nel nostro origami che ci sono pieghe attive e non. Farebbe comodo quindi poter dare un peso ad ogni equazione in modo da poterne “modellare” il comportamento in un determinato punto.
In poche parole, stiamo cercando una funzione che trasformi le nostre funzioni da lineari a non lineari.
La risposta si chiama funzione di attivazione $a(x)$: una famiglia di strumenti capaci di introdurre esattamente la discontinuità cercata. Nel nostro caso useremo la Rectified Linear Unit ($ReLU$).
$$ a(x) = ReLU(x) = \begin{cases} 0 & x < 0 \\ x & x \ge 0 \end{cases} $$Se $x$ è maggiore di zero allora $y = x$, altrimenti, se $x$ è minore di zero allora $y = 0$.
Quindi adesso possiamo riscrivere:
$$ \begin{align*} h_1 &= a(x \alpha_1 + \beta_1) \\ h_2 &= a(x \alpha_2 + \beta_2) \\ h_3 &= a(x \alpha_3 + \beta_3) \end{align*} $$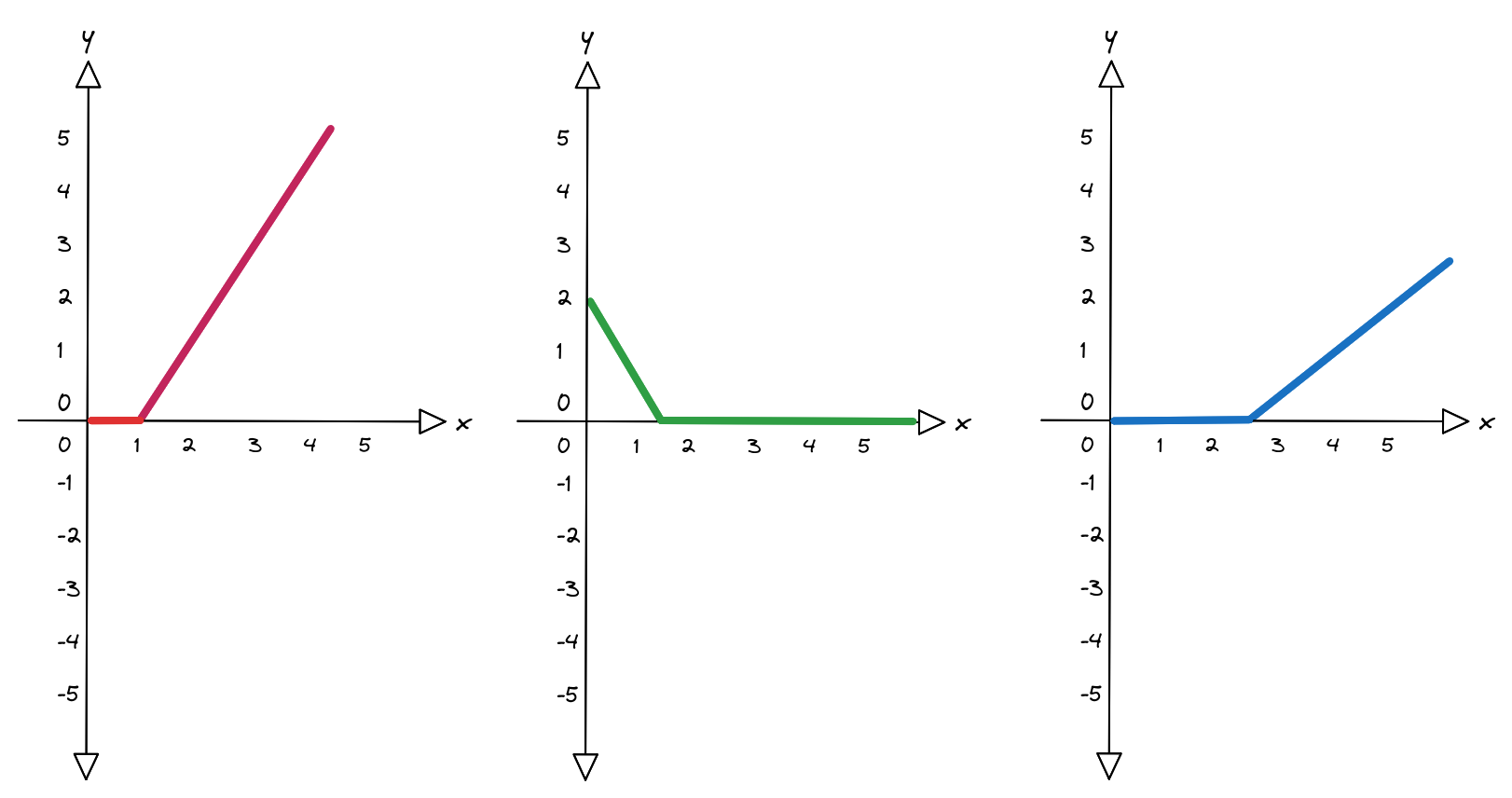
Ora dobbiamo unire le tre equazioni, ma prima dobbiamo capire come pesare l’effettivo contributo di ognuna. Il modo più semplice è aggiungere dei nuovi parametri da cercare in modo da quantificare questo contributo. Chiameremo $\phi_n$ questo insieme di parametri e li useremo all’interno della combinazione:
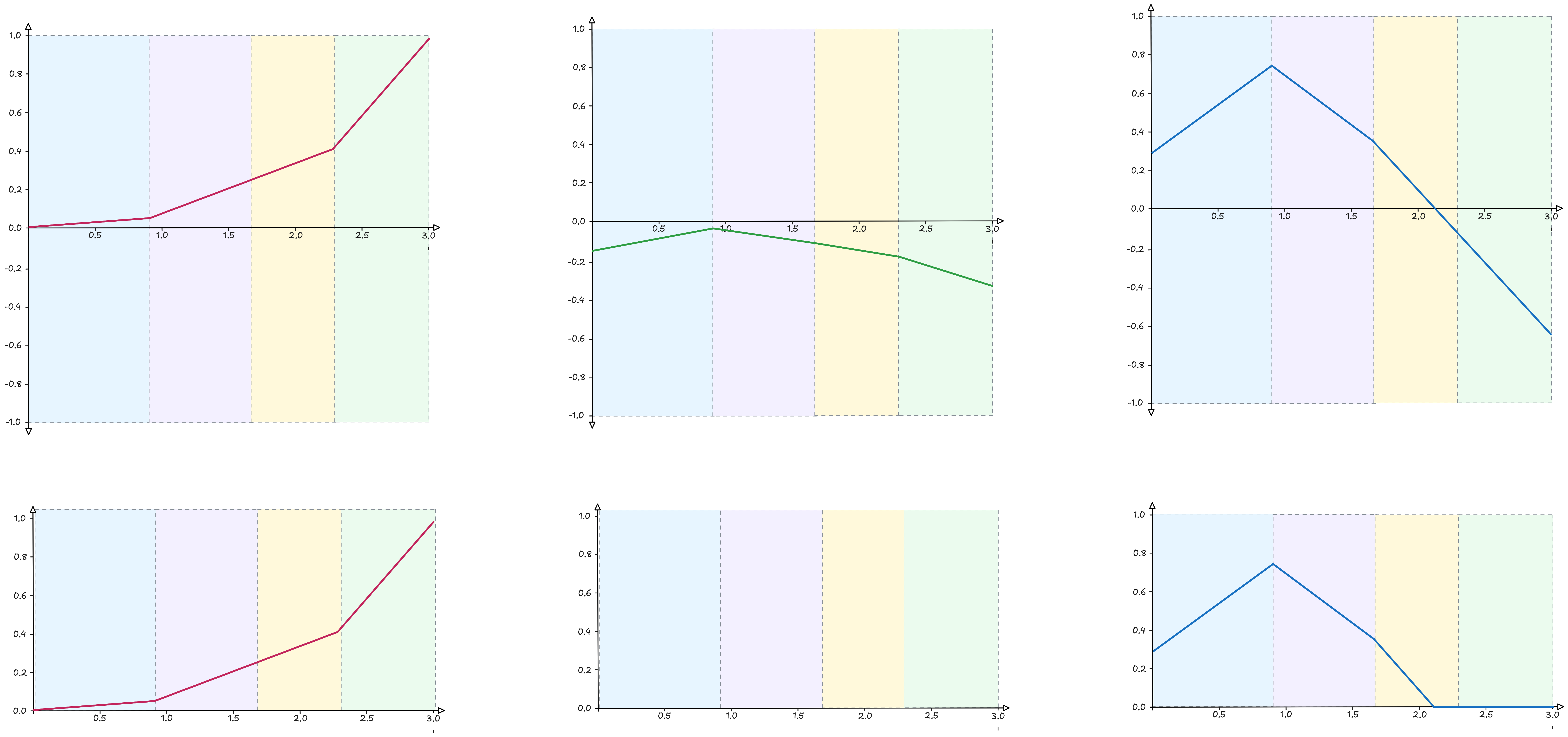
$$ \begin{align*} y &= \phi_0 + \phi_1 h_1 + \phi_2 h_2 + \phi_3 h_3 \\ &= \phi_0 + \phi_1 a(x \alpha_1 + \beta_1) + \phi_2 a(x \alpha_2 + \beta_2) + \phi_3 a(x \alpha_3 + \beta_3) \end{align*} $$Cerchiamo di capire bene cosa è successo finora:
- abbiamo preso una retta
- l’abbiamo trasformata in tre pezzi piegati dove:
- i parametri $\alpha$ e $\beta$ definiscono le funzioni base
- i parametri $\phi_n$ decidono quanto ciascuna funzione contribuisce al risultato finale
- infine abbiamo combinato linearmente questi tre pezzi
Il risultato è una funzione finale fatta di al massimo quattro tratti lineari su (x).
Praticamente come nell’origami, abbiamo creato quattro zone all’interno delle quali cominciare a definire le pieghe necessarie a raggiungere il risultato cercato.
La differenza da notare è che nel caso dell’origami abbiamo due pieghe attive e due inattive; nel nostro origami matematico invece tutte le pieghe sono attive e contribuiscono alla forma finale.
Vorrei concludere questo paragrafo aggiungendo un ultimo elemento di complessità. Di seguito è riportata la formula che generalizza quanto scritto fin’ora:
$$ y = \phi_0 + \phi_1 h_1 + \ldots + \phi_n h_n = \phi_0 + \sum_{i=1}^{n} \phi_i h_i $$Il simbolo $\sum$ (sigma) non è altro che un modo compatto per descrivere una somma di elementi da 1 a $n$.
L’infinito non è una cosa, ma una possibilità che non si esaurisce mai
La citazione corretta del matematico Henri Poincaré in realtà è questa:
In realtà l’infinito non esiste, e quando parliamo di una collezione infinita, intendiamo una collezione alla quale possiamo aggiungere continuamente nuovi elementi. (La Logica dell’Infinito, 1912)
Poincaré concepiva l’infinito non come un oggetto compiuto ma come un processo: qualcosa a cui si aggiunge, senza mai esaurirlo. Mi piace usare questa idea (pur essendo stata messa da parte dalla matematica del ‘900, in favore della concezione di infinito di Cantor) per descrivere come una rete neurale scomponga un’informazione complessa per livelli successivi, ciascuno dei quali non esaurisce il significato ma lo passa al successivo, arricchito. Se non altro è un’associazione di pensiero molto… umana.
Ma torniamo al nostro origami. Siamo arrivati ad un punto in cui i passaggi precedenti determineranno quelli successivi. Le pieghe grossolane di certo non definiscono una figura, ma, come già detto, ognuna di quelle aree generate sarà la base per costruire dettagli sempre più raffinati.
Anche per il nostro modello la situazione non cambia: dobbiamo raffinare il precedente risultato per renderlo ancora più vicino alla curva target.
Cominciamo costruendo una nuova serie di funzioni in grado di generare altre “pieghe” all’interno delle precedenti, ovvero un secondo livello di funzioni che avranno come input il risultato del livello precedente.
Prima di procedere, adottiamo un espediente per distinguere i parametri tra i livelli: useremo il parametro primo $p'$ per il primo livello e il parametro secondo $p''$ per il secondo livello.
Riscriviamo il primo livello in questo modo:
$$ \begin{align*} h_1' &= a(x \cdot \alpha_1' + \beta_1') \\ h_2' &= a(x \cdot \alpha_2' + \beta_2') \\ h_3' &= a(x \cdot \alpha_3' + \beta_3') \end{align*} $$Passiamo quindi al secondo livello. Anche in questo caso il risultato arriva da una funzione lineare trasformata da una funzione di attivazione $a(x) = ReLU(x)$.
$$ \begin{align*} h_1'' &= a(y' \cdot \alpha_1'' + \beta_1'') \\ h_2'' &= a(y' \cdot \alpha_2'' + \beta_2'') \\ h_3'' &= a(y' \cdot \alpha_3'' + \beta_3'') \end{align*} $$Ma noi sappiamo già come si calcola $y'$: è la combinazione lineare delle funzioni del primo livello, ovvero $y' = \phi_0' + \phi_1' h_1' + \phi_2' h_2' + \phi_3' h_3'$.
Sostituendo questa espressione all’interno di ogni $h_n''$ otteniamo:
$$ \begin{align*} h_1'' &= a(\phi'_{10} + \phi'_{11} h_1' + \phi'_{12} h_2' + \phi'_{13} h_3') \\ h_2'' &= a(\phi'_{20} + \phi'_{21} h_1' + \phi'_{22} h_2' + \phi'_{23} h_3') \\ h_3'' &= a(\phi'_{30} + \phi'_{31} h_1' + \phi'_{32} h_2' + \phi'_{33} h_3') \end{align*} $$Attenzione a un passaggio sottile: nella definizione iniziale ogni $h_n''$ dipendeva soltanto dallo scalare $y'$. Una volta espanso $y'$, invece, ogni unità del secondo livello dipende separatamente da tutte e tre le $h'$ del primo. Trattando i $\phi'_{nj}$ come parametri liberi e indipendenti facciamo proprio questo salto: passiamo da un singolo “collo di bottiglia” a un livello pienamente connesso.
Il nostro nuovo output $y''$ avrà quindi la seguente forma:
$$ y'' = \phi''_0 + h_1'' \phi_1'' + h_2'' \phi_2'' + h_3'' \phi_3'' $$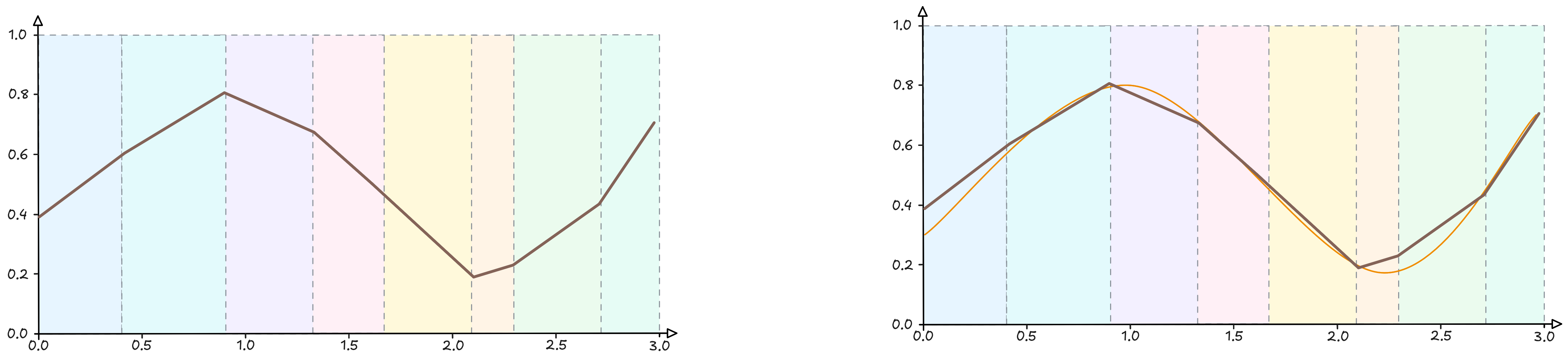
Due osservazioni importanti emerse da quest’ultimo passaggio:
-
Le nuove funzioni operano all’interno delle quattro zone definite dal precedente livello creandone di nuove. Quindi alla fine otterremo un’approssimazione della curva sempre più vicina all’originale, componendo tanti piccoli pezzi ben definiti.
-
Nel secondo livello è capitato che la funzione $h_2''$ non risulta attiva (se non è chiaro il perché, riprendete la descrizione della funzione $ReLU$). Significa che il primo layer ha rilevato una caratteristica, ma il layer successivo ha deciso che quella caratteristica, da sola o in combinazione con le altre, non è stata sufficiente per attivarsi.
Arrivati a questo punto potremmo continuare all’infinito (questa volta secondo Cantor), per arrivare ad una rappresentazione sempre più raffinata della curva, ma non è importante ai fini del discorso.

Vorrei che fosse chiaro però cosa abbiamo realizzato da un punto di vista matematico: un’enorme composizione di semplici funzioni matematiche.
E quindi queste reti neurali….
Ora, mettiamo insieme ogni elemento di questa composizione di funzioni in una rappresentazione grafica che aiuti a visualizzare meglio.
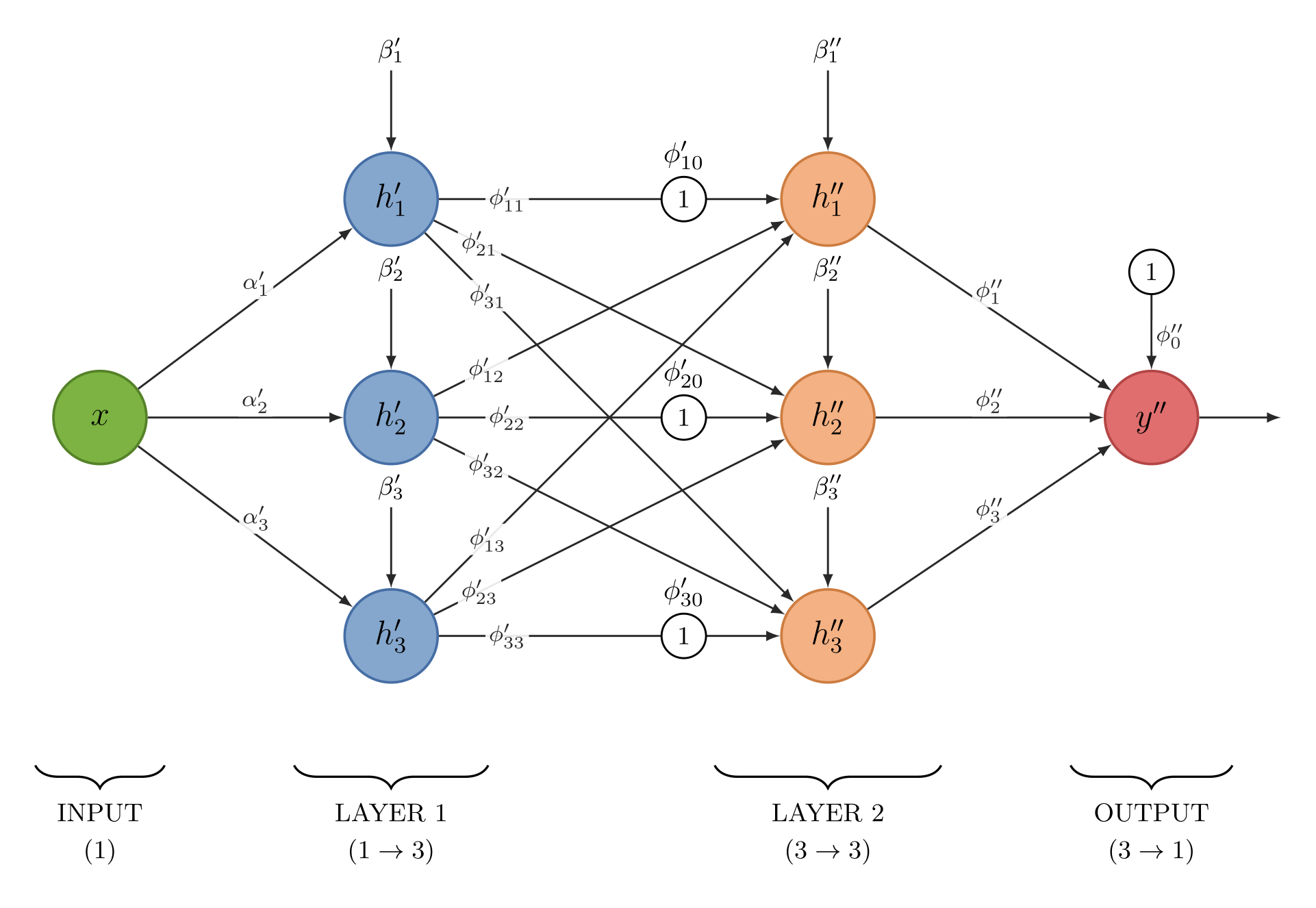
E alla fine ecco la rete neurale.
No, non vedrete raffigurazioni di sinapsi, sono ormai convinto che sia una rappresentazione fuorviante. Dal mio punto di vista, una rete neurale sta al cervello umano come un piccione sta ad un aereo. Sicuramente i volatili hanno ispirato la costruzione degli aerei, ma passare sotto uno stormo di aerei non è sicuramente altrettanto rischioso che passare sotto uno stormo di piccioni dopo che hanno mangiato.
Dopotutto la definizione di rete neurale è formalizzata in un teorema, frutto di contributi a partire da George Cybenko nel 1989 fino ad Allan Pinkus nel 1999.
Teorema di Approssimazione Universale
Per qualsiasi funzione continua su un sottoinsieme compatto di $\mathbb{R}^n$ e per qualsiasi precisione $\varepsilon > 0$ arbitrariamente specificata, esiste una rete con un unico strato nascosto contenente un numero finito di unità nascoste con una funzione di attivazione non polinomiale, capace di approssimare uniformemente la funzione data entro tale precisione.
Possiamo riscriverla in modo più semplice, affermando che per quanto complicata possa essere una funzione continua, esiste sempre una rete neurale anche con un solo strato nascosto, in grado di approssimarla con la precisione che vogliamo, purché usiamo abbastanza neuroni e una funzione di attivazione adeguata.
In altre parole: le reti neurali sono approssimatori universali. Non importa quale forma abbia la funzione che vogliamo imparare, la rete può sempre avvicinarsi ad essa quanto desideriamo, semplicemente aumentando il numero di unità nascoste.
Sono convinto che la capacità di dare una rappresentazione intuitiva delle reti neurali si sia rotta proprio in questo punto, e che il problema stia nella scelta del vocabolario. Chiamare “neuroni” le unità di calcolo e “apprendimento” il processo di ottimizzazione ha sicuramente reso chiara l’ispirazione e ha aiutato a diffondere la tecnologia, ma ha reso più difficile capire davvero cosa succede. Un neurone artificiale non pensa, non percepisce, non ricorda: esegue un’operazione su un numero e passa il risultato al livello successivo. Il machine learning non impara come impara un bambino: aggiusta parametri finché l’errore non scende sotto una soglia accettabile. La matematica era accessibile, il vocabolario l’ha resa opaca.
Intendiamoci, questo non rende le reti neurali degli oggetti meno complessi, ma va capito dove risiede la complessità. Cerchiamo modelli matematici in grado di catturare tanto la topologia di una semplice curva, quanto quella di costruzioni estremamente complesse di cui vediamo solo i risultati e che facciamo fatica a immaginare dall’interno. So che detta così sembra una contraddizione. In realtà è un po’ come in astrofisica: ridurre anni di ricerca alla frase “c’è vita su quel pianeta” fa perdere la profondità di tutto quello che si è studiato e di quanto c’è ancora da capire.
Ma non finisce mica qui
Nell’imparare un origami cominciamo a creare pieghe sempre più piccole per cercare di arrivare ad una configurazione geometrica in grado di catturare l’essenza della figura originale. Il risultato finale non è quindi una rappresentazione perfettamente identica, quanto piuttosto un insieme coerente di particolari che ci fanno dire: “questo è un orsacchiotto coccoloso” oppure “questo è un grizzly affamato decisamente poco coccoloso”.
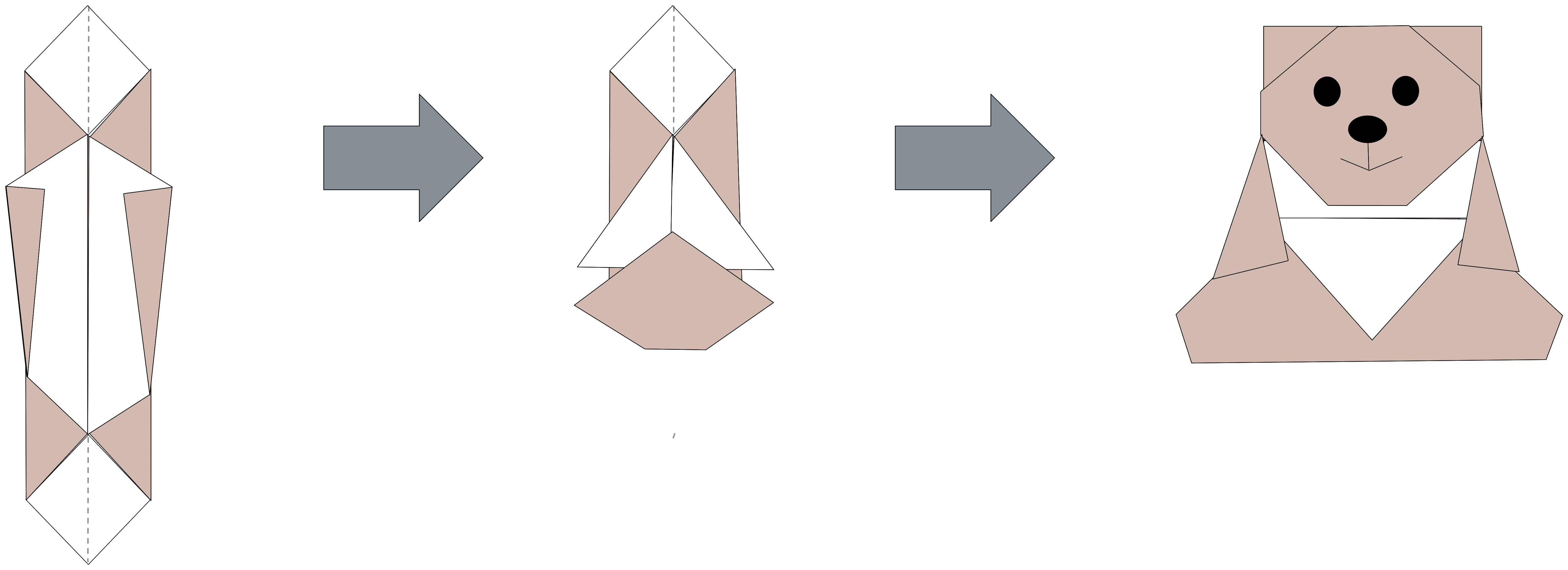
Perdonatemi, ho velocizzato i passaggi. Chi volesse approfondire lo schema di questo origami può trovarlo qui: https://www.supercoloring.com/it/media/paper-craft/456115/istruzioni-per-creare-un-origami-a-orsacchiotto
Lo stesso vale per il nostro modello. Ogni livello di funzioni $h_n$ si specializza su una zona precisa dello spazio dei dati: ciascuna unità si attiva solo quando l’input rientra in quella zona, restando inattiva altrimenti. In questo senso potremmo dire che ogni unità “riconosce” una configurazione specifica; tutto il resto viene ignorato. È questa selettività strutturale, moltiplicata per migliaia di unità e decine di livelli, a dare alla rete la sua capacità di approssimare funzioni complesse. Il tutto fino ad arrivare ad un risultato che ci sembra accettabile dal punto di vista dell’accuratezza, con un margine di errore trascurabile.
E come si fa a dare forma a questi due concetti? Questo lo vedremo nella seconda parte.
Ma posso comunque darvi un’anticipazione. Non sono bravo con gli origami e il mio primo tentativo è quasi sempre un disastro.

Sono talmente scarso da dovermi far fare da un’AI l’immagine di un origami fatto male. Ma sicuramente è una questione di parametri e di come cercarli.
Parole chiave
- Layer (strato): un livello della rete neurale composto da un insieme di unità nascoste che operano in parallelo sullo stesso input. I layer si concatenano: l’output di uno diventa l’input del successivo.
- Unità nascosta (hidden unit): un neurone appartenente a uno strato intermedio della rete neurale, non direttamente visibile né in input né in output.
- Funzione lineare: una funzione della forma $f(x) = ax + b$, che produce una retta nel piano.
- Funzione di attivazione: una funzione non lineare applicata all’output di ogni unità nascosta per introdurre non linearità nel modello.
- ReLU (Rectified Linear Unit): una funzione di attivazione definita come $f(x) = \max(0, x)$. Restituisce il valore invariato se positivo, altrimenti lo azzera, “troncando” la funzione sotto lo zero.
- Troncamento (clipping): il processo con cui la ReLU azzera la parte negativa di una funzione lineare, rendendola piatta al di sotto dello zero.
- Giunzione (joint/kink): il punto in cui la funzione cambia pendenza, cioè dove la retta attraversa lo zero e viene troncata dalla ReLU.
- Regione lineare: un intervallo dell’input in cui la funzione di output si comporta in modo lineare, ovvero tra due giunzioni consecutive.
- Schema di attivazione (activation pattern): la combinazione di unità attive e inattive in un dato intervallo dell’input.
- Unità attiva/inattiva: un’unità nascosta è detta attiva quando il suo valore non viene troncato dalla ReLU (zona positiva), e inattiva quando viene azzerata (zona negativa).
- Parametri φₙ: i pesi con cui ciascuna retta troncata contribuisce alla funzione di output finale.
- Parametro di offset φ₀: una costante additiva che sposta verticalmente l’intera funzione di output.